Uji T sebagai salah satu metode analisis uji beda sering digunakan untuk mengetahui ada tidaknya perbedaan antar kelompok. Artikel ini disajikan secara rinci mengenai Uji T Independen dan Dependen, adapun bahasan utama yaitu sebagai berikut :
- Perbedaan Uji T Independen dan Dependen
- Contoh Kasus dan Penyelesaian pada Uji T Independen
- Contoh Kasus dan Penyelesaian pada Uji T Dependen
- Asumsi Uji T
1. PERBEDAAN UJI T INDEPENDEN DAN UJI T BERPASANGAN
Pengujian perbedaan yang signifikan antara suatu kelompok data secara statistik, maka dapat menggunakan metode analisis uji beda. Salah satu uji statistik yang dapat digunakan adalah uji T atau T-Test.
Uji T digunakan untuk membandingkan rata-rata dari satu populasi data atau dua populasi data. Dengan kata lain, uji T bertujuan untuk mencari tahu perbedaan rata-rata antara data yang dibandingkan. Berikut merupakan perbedaan uji-t berdasarkan skala data:
Tabel 1. Perbedaan Uji T independent dan dependen
| Skala Data | Uji-T | |
| Dependent sample | Independent sample | |
| Interval, rasio | Paired sample T-test | Independent sample T-test |
| Nominal | Mc Nemar | Chi Kuadrat Fisher Exact |
| Ordinal | Sign Test Wilcoxon Test | Median Test U-Test (Mann Whitney) Kolmogorov Smirnov Wald Wolfowitz |
| Dependent sample | Independent sample | |
| Jenis Data | Menggunakan sampel yang berkorelasi | Menggunakan sampel bebas |
| Tujuan | Mengetahui terdapat atau tidaknya perbedaan yang signifikan antar kedua sampel | Mengetahui terdapat atau tidaknya perbedaan rata-rata kedua sampel |
| Pengambilan keputusan | Membandingkan nilai statistik uji t dengan t-tabel | Ditunjukkan oleh p-value. |
2. CONTOH KASUS UJI T INDEPENDEN
Berikut merupakan data kecepatan mobil A dan mobil B dengan menggunakan bahan bakar premium. Ingin dibandingkan peforma kedua tipe mobil yaitu A dan B. Apakah terdapat perbedaan antara kedua jenis mobil tersebut?
Tabel 2.1 Data Uji T Independen
| NO | A | B |
| 1 | 23 | 28 |
| 2 | 20 | 12 |
| 3 | 18 | 15 |
| 4 | 24 | 13 |
| 5 | 17 | 13 |
| 6 | 27 | 10 |
| 7 | 16 | 18 |
| 8 | 12 | 20 |
| 9 | 23 | 13 |
| 10 | 24 | 12 |
| 11 | 26 | 22 |
| 12 | 13 | 27 |
| 13 | 23 | 22 |
| 14 | 27 | 14 |
| 15 | 30 | 20 |
| 16 | 15 | 18 |
| 17 | 18 | 24 |
| 18 | 20 | 30 |
| 19 | 17 | 17 |
| 20 | 13 | 26 |
| 21 | 22 | 22 |
| 22 | 24 | 14 |
| 23 | 26 | 14 |
| 24 | 17 | 10 |
| 25 | 21 | 30 |
| 26 | 28 | 14 |
| 27 | 24 | 23 |
| 28 | 13 | 21 |
| 29 | 20 | 19 |
| 30 | 27 | 12 |
- Asumsi Normalitas Data
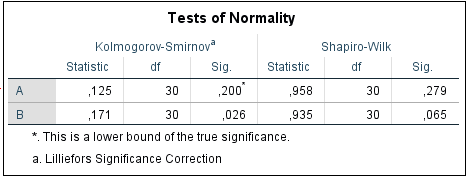
Banyaknya sampel yang digunakan pada masing-masing kelompok tipe mobil yaitu sebanyak 30 sampel maka digunakan uji Saphiro Wilk. Hipotesis asumsi normalitas data adalah sebagai berikut.
H0: Data menyebar normal
H1: Data tidak menyebar secara normal
Daerah Kritis:
Tolak H0 apabila p-value < ∝
| Jenis Mobil | P-value |
| A | 0,279 |
| B | 0,065 |
Berdasarkan tabel di atas diketahui bahwa p-value dari jenis mobil A maupun B lebih besar dari 0,05 maka gagal tolak H0 sehingga dapat disimpulkan bahwa data menyebar secara normal.
- Asumsi Homogenitas Data
Uji asumsi homogenitas data yang digunakan yaitu uji Levene. Hipotesis asumsi normalitas data adalah sebagai berikut.
H0: Ragam data bersifat homogen
H1:Ragam data bersifat heterogen
Daerah Kritis:
Tolak H0 apabila p-value < ∝
|
Uji |
P-value |
|
Levene |
0,283 |
Berdasarkan tabel di atas diketahui bahwa p-value lebih besar dari 0,05 maka gagal tolak H0 sehingga dapat disimpulkan bahwa ragam data bersifat homogen atau asumsi homogenitas data sudah terpenuhi.
- Uji t Independen
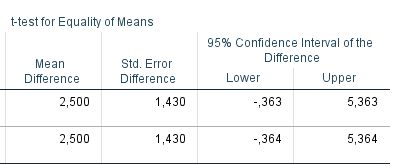
Tolak H0 apabila p-value < ∝
|
t hitung |
df |
P-value |
Mean difference |
|
1,748 |
58 |
0,086 |
2,500 |
Berdasarkan tabel di atas dapat diketahui bahwa p-value kurang dari ∝ maka tolak H0 sehingga dapat disimpulkan sudah terdapat cukup bukti bahwa terdapat perbedaan rata-rata kecepatan jenis mobil A dan B. Selain itu, mean difference sebesar 2,500 artinya selisih antara rata-rata kecepatan mobil A dan B sebesar 2,500 km/jam.
3. CONTOH KASUS UJI T DEPENDEN
Seorang mahasiswa dalam penelitiannya ingin mengetahui apakah terdapat perbedaan rata-rata nilai Kuis Statistika Matematika I antara sebelum diadakan kegiatan responsi dengan sesudah diadakan kegiatan responsi di Departemen Statistika FMIPA UB. Penelitian ini menggunakan sampel sebanyak 13 responden. Data yang didapat sebagai berikut.
Tabel 3.1 Data Uji T Dependen
|
Mahasiswa |
Sebelum Responsi |
Sesudah Responsi |
|
1 |
45 |
70 |
|
2 |
50 |
65 |
|
3 |
60 |
70 |
|
4 |
55 |
85 |
|
5 |
65 |
60 |
|
6 |
70 |
60 |
|
7 |
50 |
70 |
|
8 |
55 |
55 |
|
9 |
45 |
60 |
|
10 |
50 |
55 |
|
11 |
75 |
85 |
|
12 |
40 |
70 |
|
13 |
50 |
8 |
- Asumsi Normalitas Data
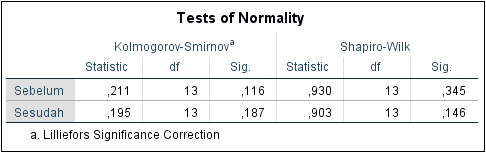 Banyaknya sampel yang digunakan pada nilai sebelum dan sesudah yaitu sebanyak 13 sampel maka digunakan uji Saphiro Wilk. Hipotesis asumsi normalitas data adalah sebagai berikut.
Banyaknya sampel yang digunakan pada nilai sebelum dan sesudah yaitu sebanyak 13 sampel maka digunakan uji Saphiro Wilk. Hipotesis asumsi normalitas data adalah sebagai berikut.
H0: Data menyebar normal
H1: Data tidak menyebar secara normal
Daerah Kritis:
Tolak H0 apabila p-value < ∝
Nilai
P-value
Sebelum Responsi
0,345
Sesudah Responsi
0,146
Berdasarkan tabel di atas diketahui bahwa p-value sebelum maupun sesudah lebih besar dari 0,05 maka gagal tolak H0 sehingga dapat disimpulkan bahwa data menyebar secara normal.
 · Uji t Dependen
· Uji t Dependen
Hipotesis:
H0: µA = µB (Tidak terdapat perbedaan nilai sebelum dan
sesudah responsi)
H1: µA ≠ µB (Terdapat perbedaan nilai sebelum dan sesudah
responsi)
Daerah Kritis:
Tolak H0 apabila p-value < ∝t hitung
df
P-value
Mean difference
-3,610
12
0,004
-13,462
Berdasarkan tabel di atas dapat diketahui bahwa p-value kurang dari ∝ maka tolak H0 sehingga dapat disimpulkan sudah terdapat cukup bukti bahwa terdapat perbedaan nilai sebelum dan sesudah responsi. Selain itu, mean difference sebesar -13,462 artinya selisih antara rata-rata sebelum dan sesudah adalah 13,5.
4. ASUMSI UJI T
Asumsi-asumsi utama dari uji T adalah sebagai berikut.
1. Asumsi Normalitas
Salah satu asumsi penting dalam uji-t adalah bahwa data dalam setiap kelompok harus mengikuti distribusi normal. Artinya, data seharusnya terdistribusi secara merata di sekitar nilai rata-rata, dengan sebagian besar data berada di sekitar rata-rata dan lebih sedikit data di ekstrem.Mengapa Asumsi Normalitas Penting?
Asumsi normalitas penting karena uji-t memerlukan normalitas data untuk memberikan hasil yang akurat. Ini memengaruhi interpretasi hasil uji-t dan keandalan temuan. Jika data tidak mengikuti
distribusi normal, hasil uji-t mungkin tidak tepat.
Cara Memeriksa Asumsi Normalitas
Ada beberapa cara untuk memeriksa apakah data kita memenuhi
asumsi normalitas:
1. Histogram :
Anda dapat membuat histogram data Anda dan memeriksa apakah distribusi data mirip dengan kurva normal.
2. Q-Q Plot :
Quantile-quantile plot membandingkan distribusi data dengan distribusi normal. Jika titik dalam plot ini mengikuti garis lurus, data mungkin mengikuti distribusi normal.
3. Uji Statistik :
Banyak ahli yang mengembangkan cara-cara menguji normalitas. Cara pengujian yang dikembangkan tersebut diantaranya meliputi Uji Kolmogorov-Smirnov, Uji Liliefors, dan Uji Shapiro-Wilk (Usmadi, 2020).
Menurut Karomah dkk. (2005), uji Shapiro-Wilk banyak dipilih karena kekuatan uji yang dimiliki lebih baik daripada uji alternatif lainnya. Uji ini digunakan saat sampel berukuran 50, sedangkan jika sampel berukuran > 100 maka digunakan Kolmogorov Smirnov.Saphiro Wilk
Hipotesis :
H0: galat berdistribusi normal
H1: galat tidak berdistribusi normal
Statistik Uji :
Keterangan :

Kriteria Uji :
Tolak H0 saat p-value < ∝ (0.05)
Terima H0 saat p-value > ∝ (0.05)
2. Asumsi Homogenitas Varians
Uji asumsi homogenitas diperlukan dalam mengetahui kesamaan ragam populasi. Analisis ini merupakan syarat yang harus dipenuhi saat akan melakukan analisis independen sample t-test dan ANOVA. Apabila dua atau lebih kelompok data memiliki ragam/varian yang sama besar nilainya, maka data sudah dianggap sebagai data homogen sehingga analisis homogenitas tidak perlu lagi dilakukan (Usmadi, 2020). Berikut adalah beberapa langkah yang dapat diambil dalam uji homogenitas varians data:1. Visualisasi Data
Langkah pertama adalah memvisualisasikan data, seperti dengan menggunakan box plot atau scatter plot. Ini dapat membantu untuk melihat apakah ada indikasi bahwa varians antara kelompok atau perlakuan tidak seragam.
2. Uji Statistik
Uji statistik untuk menguji homogenitas varians salah satunya adalah uji Levene atau uji Bartlett. Uji Levene lebih tahan terhadap asumsi normalitas, sementara uji Bartlett lebih tepat jika data yang digunakan memenuhi asumsi normalitas. Langkah-langkah uji Levene adalah sebagai berikut.
Hipotesis :

Statistik Uji :



Kriteria Uji :
3. Transformasi Data
Jika uji homogenitas varians menunjukkan ketidakseragaman varians, dapat mencoba transformasi data untuk membuat variansnya menjadi lebih homogen. Beberapa transformasi yang umum digunakan adalah transformasi logaritma atau transformasi kuadrat akar.
4. Uji Alternatif
Jika transformasi data tidak efektif atau tidak mungkin, dapat mempertimbangkan penggunaan uji non-parametrik, seperti uji Kruskal-Wallis, yang lebih tahan terhadap asumsi homogenitas varians. Langkah-langkah dalam uji Kruskal-Wallis adalah sebagai berikut.
Hipotesis :

Statistik Uji :


Kriteria Uji:
5. Pertimbangkan Desain Penelitian
Jika uji homogenitas varians masih menunjukkan perbedaan yang signifikan, mungkin perlu mempertimbangkan desain ulang penelitian. Ini bisa melibatkan pengaturan ulang kelompok atau perlakuan, atau menambahkan kontrol yang lebih baik untuk mengurangi variabilitas.
-
DAFTAR PUSTAKA
Usmadi, U. 2020. Pengujian Persyaratan Analisis (Uji Homogenitas dan Uji Normalitas). Inovasi Pendidikan, 7(1).
Kadir. 2015. Statistika Terapan: Konsep, Contoh, dan Analisis Data dengan Program SPSS/Lisrel dalam Penelitian. Jakarta: Rajawali Pers.
Widarjono, Agus. 2015. Statistika Terapan dengan Excel & SPSS. Yogyakarta: UPP
STIM YKPN. Researchgate.net. (Diakses pada tanggal 24 Oktober 2023)